🔍 Web search with Google • Bing • DuckDuckGo • Marginalia • Reddit • Spotify • TikTok • Tootfinder • X • Yandex • Youtube • YTM
This you find in the 🏛️ Agora
🗣️ Stoas for [[@agora/2022 12 10]]
A Stoa is a public space where people can meet and collaborate.
📖 Document at https://doc.anagora.org/2022-12-10
📹 Meeting at https://framatalk.org/2022-12-10
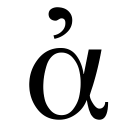
Loading Agora node...
What could we show here?